Machine Learning - Data Mining - Big Data Processing
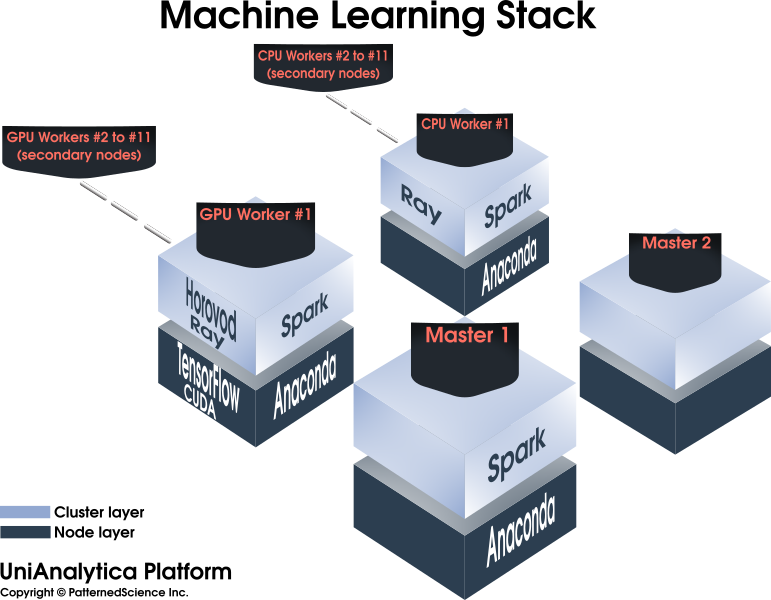
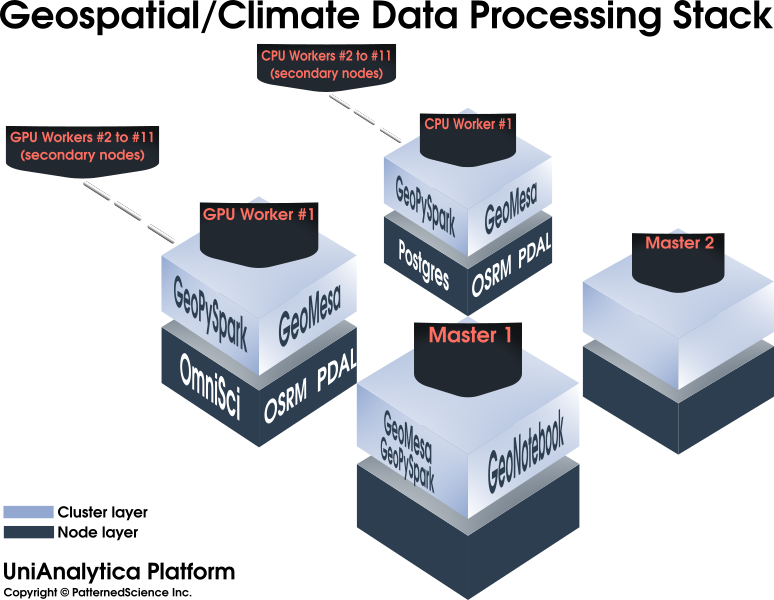
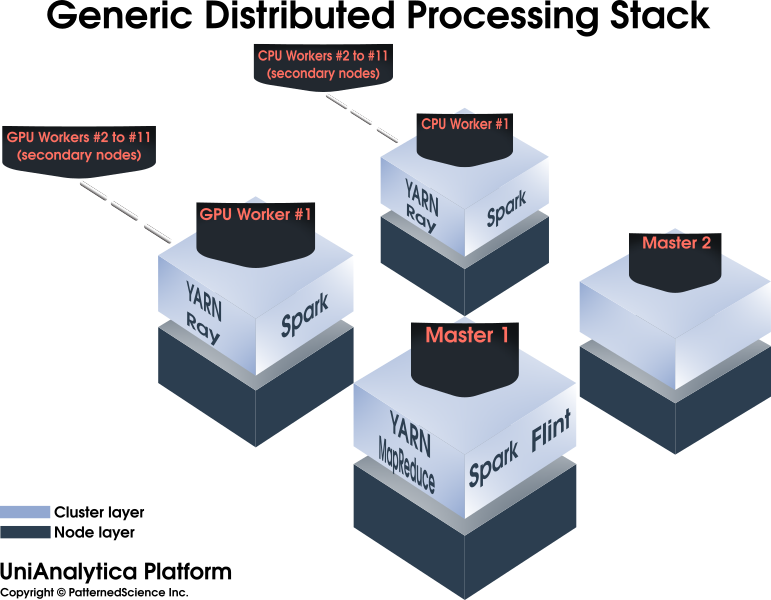
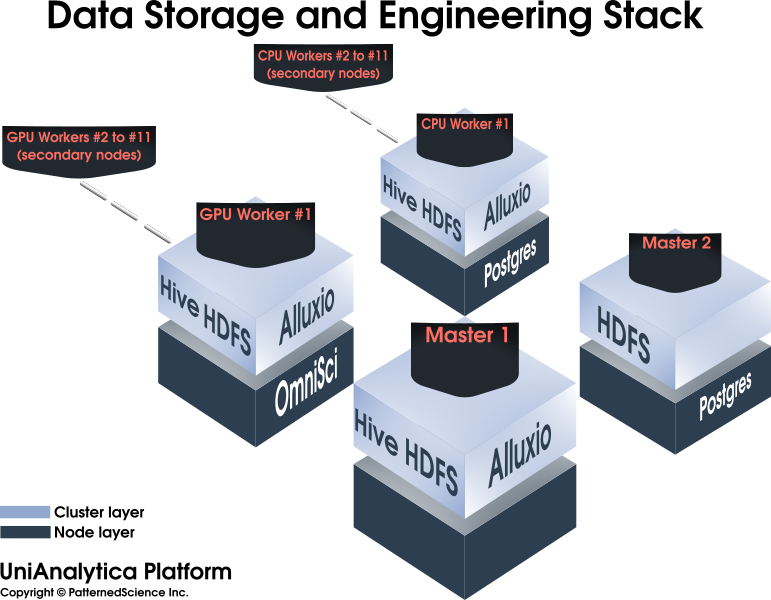
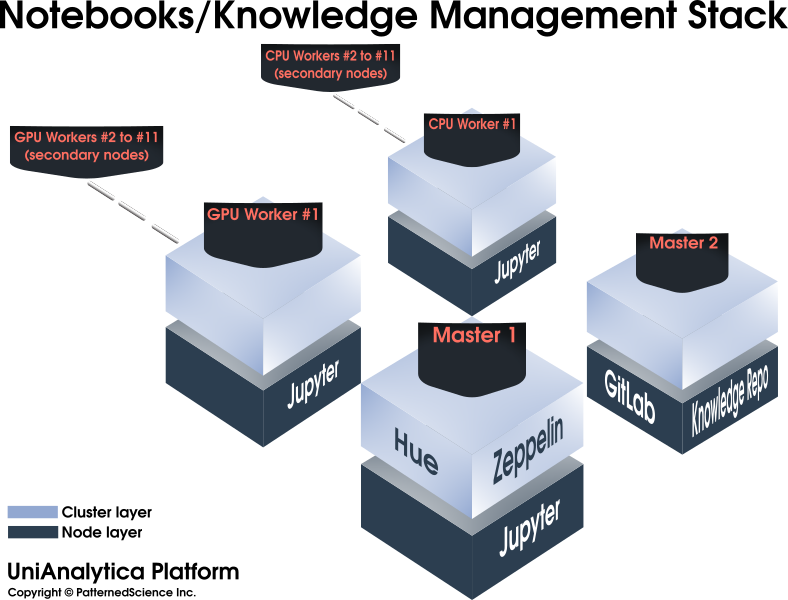
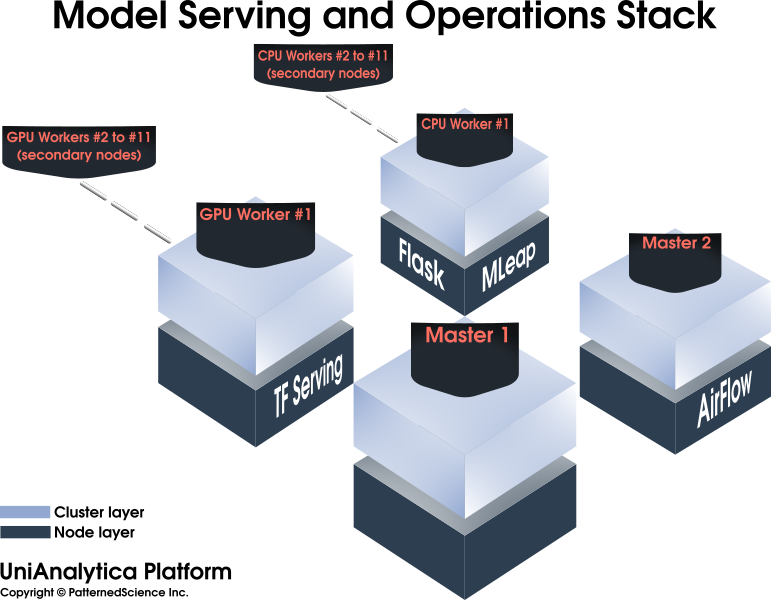
An advanced Data Science cluster/platform, enabling and accelerating machine learning and Big Data mining projects, among others.
Wide, out-of-the-box support for use cases involving time series data (IoT and finance), GIS data (GPS/LiDAR), and images (object detection).
Composed of 100% open-source, mature components, facilitating knowledge transfer and project handovers. No vendor lock-in.
Infrastructure-agnostic: on-premise or on-the-cloud installation (needs CentOS machines/VMs and access to public Internet during deployment).
Maximizing infrastructure utilization (and lowering costs) by integrating many components into a single platform.
Enterprise security: clearly understood and easily configurable security framework.
An integrated platform which allows full-scale R&D as well as functions as an initial production environment.
20+ application reference implementations covering most components and use cases (Jupyter notebooks, Zeppelin notes and Python scripts). These are all run and tested during the platform deployment so the user can use and customize them from Day 1, resulting in much shorter project durations.
Watch some tech talks presenting few key use cases/reference implementations